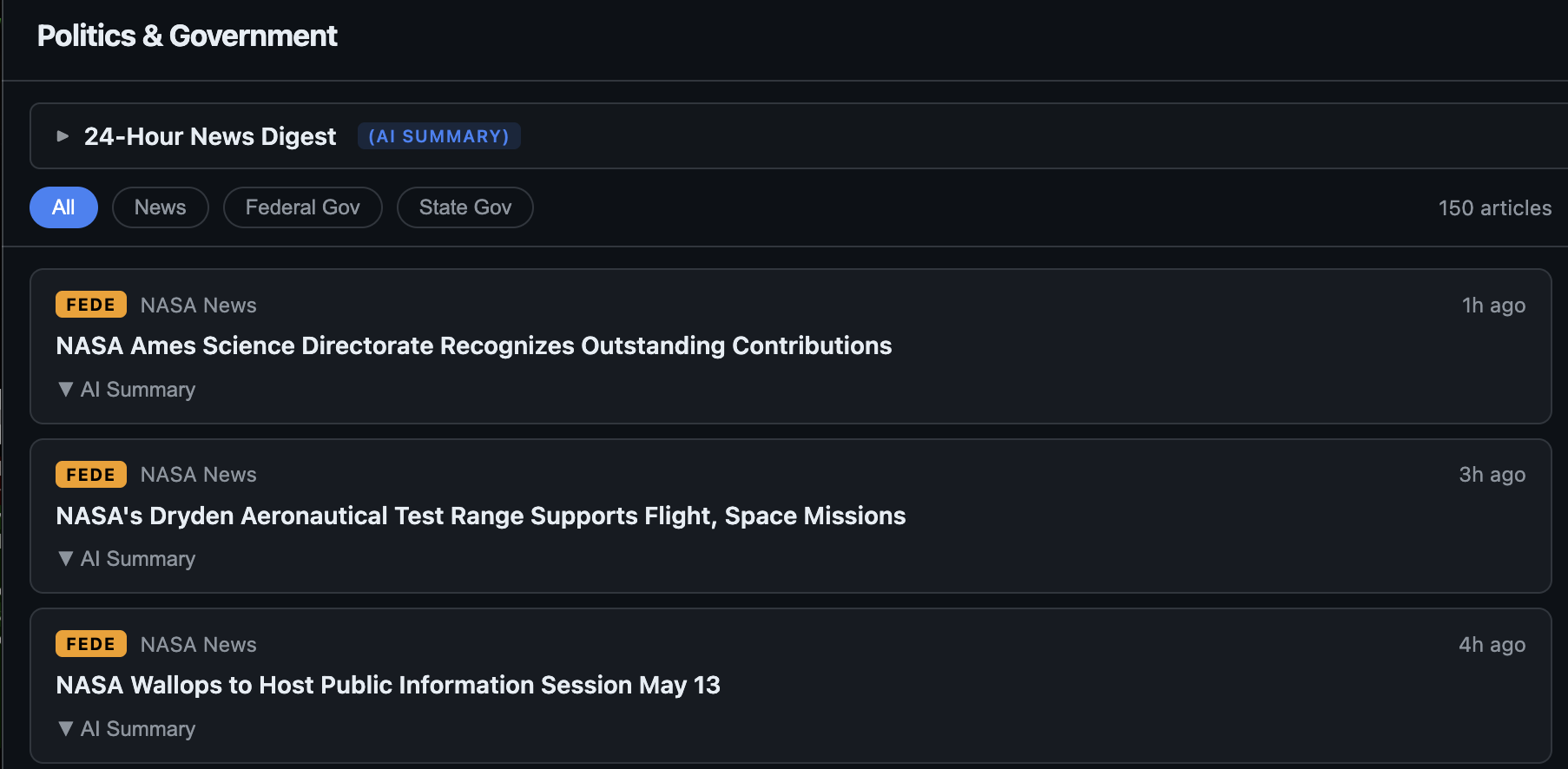
Politics Dashboard: A Self-Hosted, AI-Summarized News & X Feed Reader
Bottom line up front. I built and now open-sourced a self-hosted news dashboard that aggregates political news from RSS or FreshRSS, summarizes each article with a configurable LLM, generates a 24-hour thematic digest, and sits alongside live X/Twitter posts (with per-account AI summaries) via a self-hosted Nitter. Repository: github.com/RobertDWhite/politics-dashboard. License: MIT. Multi-arch images at ghcr.io/robertdwhite/politics-{api,ui}. The image I run in production is the same image GitHub Actions builds from main.
This post documents the architecture, the configuration model, my own deployment, and the engineering issues encountered while generalizing the project for OSS release.
Origin
I had a FreshRSS instance with several hundred feeds, organized into categories News and U.S. Government. Reading it had degraded into opening 60 tabs each morning, skimming a sentence each, and closing 55 of them. The signal-to-noise ratio was poor.
I had Ollama running locally with llama3.1:8b for unrelated work. I started piping articles through it for two-sentence summaries. Quality was acceptable: enough to triage headlines, not enough to replace reading.
V1 ran on my cluster behind Authentik in two services and a few hundred lines of code. Two categories and a few dozen X handles. It became the first tab I opened each morning. That was the moment to invest more.
Architecture
Two services, no shared state, no database.
API. FastAPI plus httpx. Polls feeds, summarizes articles, generates digests. The state is held in process memory (Python dicts plus an asyncio.Queue). Resident memory: ~150 MiB.
UI. Vite, React, TypeScript. Static SPA served by an unprivileged nginx container. nginx reverse-proxies /api/* to the API. Resident memory: ~30 MiB.
State is intentionally ephemeral. Restarting the API pod re-polls every source. The dashboard is a view over external feeds instead of a system of record. This decision keeps the operational footprint small enough to require zero PVCs and zero backup configuration.
Four loops run inside the API:
| Loop | Cadence | Role |
|---|---|---|
| Feed refresher | 15 min | Polls FreshRSS or direct RSS, merges into article store, enqueues new IDs for summarization |
| Per-article summarizer | continuous | Pulls one article off the queue, calls the LLM, stores 2–3 sentence summary keyed by article ID |
| 24-hour digest generator | 1 hour | Sends the last 24h of articles to the LLM with a structured-markdown prompt, stores the result |
| X handle summarizer | 3 hours | Fetches Nitter RSS for each handle, summarizes recent posts per account |
The digest prompt requests markdown output with ## Category headers, bolded lead phrases, and a Bottom Line closer. The front-end has a regex-based markdown renderer (~80 lines) that handles headers, bullet lists, ordered lists, and inline **bold**. No third-party markdown dependency.
Configuration model
A single config.yaml drives the application. Secrets and per-deploy overrides live in environment variables. The schema separates four concerns: title, LLM provider, feeds, and Twitter.
LLM. Two providers: openai_compatible (covers Ollama, OpenAI, vLLM, LM Studio, Together, Groq — anything with a /chat/completions endpoint) and anthropic (Messages API). One coroutine signature: chat(system, user, max_tokens) -> str. API keys come from environment variables named in the YAML.
Feeds. Two sources: rss (direct fetch of feed URLs) or freshrss (Greader API to an existing FreshRSS instance). Categories are user-defined: an arbitrary slug, a UI label, and either a list of URLs or a FreshRSS category name. The API has no opinions about reasonable category names.
Twitter. Optional. Requires a self-hosted Nitter instance — public Nitter is rate-limited to uselessness. Handle lists can be declared in YAML or pulled from environment variables via a handles_env_prefix knob, which is the path I use because it keeps handle lists in a SOPS-encrypted Kubernetes Secret.
UI. The API exposes a /config endpoint at startup. The front-end builds its category tabs, page title, and X-panel sections from that response. The same UI image works for any beat — political, scientific, hobby — without rebuilding.
Production deployment
My deployment in summary:
title: "Politics & Government"
llm:
provider: openai_compatible
base_url: http://ollama-router.ai-stack.svc.cluster.local:11434/v1
model: llama3.1:8b
feeds:
source: freshrss
freshrss:
url: http://freshrss.freshrss.svc.cluster.local/api/greader.php
username: robert
password_env: FRESHRSS_API_PASSWORD
categories:
news: { label: News, freshrss_label: News }
government: { label: Federal Gov, freshrss_label: "U.S. Government" }
state_government: { label: State Gov, freshrss_label: "Ohio State Government" }
twitter:
enabled: true
nitter_url: http://nitter.nitter.svc.cluster.local:8080
handles_env_prefix: X
categories:
politics: { label: Politics, handles: [] }
government: { label: Federal Gov, handles: [] }
state_government: { label: State Gov, handles: [] }
Three categories, ~50 X handles split across them. ArgoCD watches the manifests and auto-syncs. Images come from GitHub Actions on every push to main, multi-arch (linux/amd64, linux/arm64), tagged :main, :sha-<short>, and on tag pushes, semver.
End-to-end change cycle for a new X handle: ~30 seconds. sops --set on the secret, git push, ArgoCD applies, kubectl rollout restart deployment/politics-api -n politics so the new env var is picked up by a fresh pod.
Adding a new category requires editing the configmap and the secret, both committed to the same repo, so it is one commit and one rollout.
Engineering issues encountered
A short post-mortem on five issues that took non-trivial time. Recording them so the next person who hits them spends less.
1. Reasoning-model <think> tags appearing in summaries. When I swapped in qwen3 and deepseek-r1 variants, output started including <think>... long chain-of-thought ...</think> before the actual summary. Mitigation: a single re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL) after each LLM response, before storage or display. Any application that lets users select arbitrary models eventually hits this. It’s worth building in from day one.
2. nginx rewrite ... break halts subsequent set directives. First attempt at a runtime-configurable upstream:
location /api/ {
rewrite ^/api/(.*)$ /$1 break;
set $api_upstream ${API_UPSTREAM};
proxy_pass $api_upstream;
}
Result: proxy_pass: invalid URL prefix in "" at request time, with a warning that api_upstream was uninitialized. Root cause: set belongs to ngx_http_rewrite_module, and rewrite ... break halts further processing of that module. Fix: place set before rewrite. Documented in the nginx manual, but it’s easy to miss (at least I did).
3. nginx proxy_pass with a variable does not strip the location prefix. With a literal upstream (proxy_pass http://api:8000/;), nginx replaces the matched location prefix with the trailing slash from proxy_pass. With a variable upstream (proxy_pass $api_upstream;), nginx forwards the request URI verbatim. Result: /api/config was being forwarded as /api/config to a FastAPI app that serves at /config. All requests returned 404. Fix: an explicit rewrite before the proxy_pass. Both this and issue #2 are documented; both still cost me an hour.
4. Vite environment variables are baked at build time. The Nitter iframe URL is a frontend concern (the browser, not the API, makes that request) and must therefore be reachable from end users (the API can use a separate internal URL for its own RSS scraping). My first attempt put it in the runtime configmap. VITE_* variables are inlined into the JavaScript bundle at build time, not read at runtime. Workaround: build-arg on the UI Dockerfile, with the OSS workflow building images without it (so the published OSS image renders blank iframes unless rebuilt). Planned change for V2.1: move the iframe URL into the runtime /config payload so the published image works straight from GHCR for any user with a Nitter instance.
5. The first OSS UI image broke the production deployment. politics-ui:2.0.0 shipped with proxy_pass http://api:8000 hardcoded — correct for docker compose up (service name api) but wrong for my Kubernetes deploy (service name politics-api). The cluster sat on “Loading…” until V2.0.3 went out an hour later, after fixing issues #2 and #3 in the process. Lesson: end-to-end test the Kubernetes path before tagging an OSS release. V2.0.4 onward will go through a full test-cluster pass before tagging.
Out of scope
Four explicit non-goals.
No persistent database. Search across historical articles, trend charts over months, audit of what was on the page at a given moment — different application. Adding Postgres would change the operational character significantly. The use case (a daily front page kept current) does not justify it.
No social-media ingestion beyond Nitter. Mastodon, Bluesky, Threads each have their own auth, rate-limit, and content-shape conversations. Possible future providers.
No editorial layer. The summarization prompts request factual, neutral, specific output. Digest section names are picked by the model from the day’s news content. Whatever editorial slant the dashboard exhibits comes from the user’s feed list and handle list, both of which are configurable.
Closing observation
Most of the OSS work was not in application logic. It was in the seam between what I had built for myself and what could plausibly run for someone else without my specific FreshRSS, Ollama, Nitter, and feed list. Cleaning up that seam is roughly the entire OSS effort.
The code is a small, useful tool. I run it daily. If you do too, the categories you pick are likely the most informative thing about your configuration even more than the model selection or the feed sources. They describe what the user is paying attention to.
Source: github.com/RobertDWhite/politics-dashboard. Images:
ghcr.io/robertdwhite/politics-api,ghcr.io/robertdwhite/politics-ui(multi-arch). License: MIT.As always, if you have any questions, feel free to start a Discussion on GitHub, submit a GitHub PR to recommend changes/fixes in the article, or reach out to me directly at [email protected].
Thanks for reading!
Robert